

CLIP Based Deepfake Detection
Abstract
Abstract
Aim:
To develop an accurate Deepfake Detection Model using CLIP with a Gradio-based interface for real-time experience.
Introduction:
Deepfake images generated by advanced AI models like SDXL, SD14, and similar diffusion-based architectures pose a significant challenge in identifying manipulated content. This project leverages CLIP model to extract embeddings from both real and fake images, training a robust binary classifier to detect deepfakes.
A Gradio-based user interface is implemented to interact with the trained model for better user interface.
Literature Survey:
Traditional deepfake detection methods have largely relied on convolutional neural networks (CNNs) trained on raw pixel data or handcrafted frequency features, such as Discrete Cosine Transform (DCT).While these methods can detect artifacts introduced during the generation process, they often suffer from limited generalization, particularly when evaluated on out-of-distribution datasets.But CLIP based models performs well even for highly realistic fake images generated by DALL·E 3, Midjourney v5, and Adobe Firefly.
Dataset:
Elsa-D3 dataset contains set of a real image and four different deepfake images , which we used in our project.
Technologies used:
. Python3
. CLIP
. Gradio
Methodology :
Architecture of CLIP(Contrastive Language-Image Pretraining) Model:
Each image is passed through CLIP to obtain 768-dimensional embeddings. These embeddings represent the semantic and structural properties of the image.
Here we used image encoder in CLIP that is Vision Transformer (ViT-L/14) . The Vision Transformer (ViT) breaks the image into a grid of patches (14×14 in the original implementation). Each of these is projected via a learned linear transformation to become a patch embedding. These patch embeddings are fed into a transformer encoder network, and the token is used to predict the class probabilities.

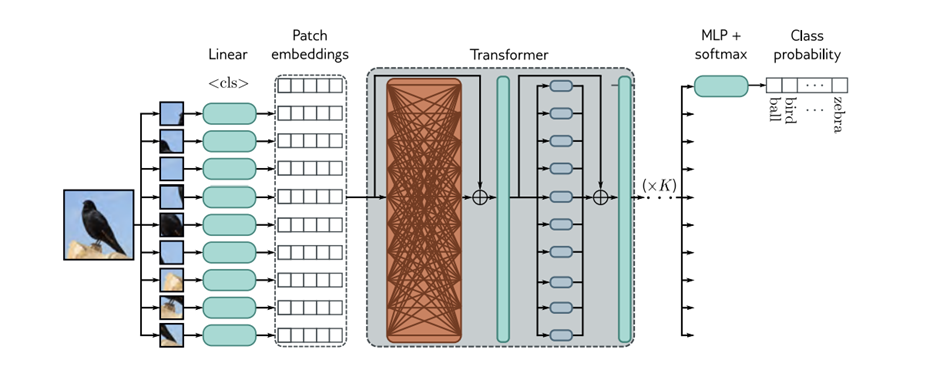
Steps and stages involved:
Image Tokenization – Convert images into patches (32x32)
Patch Embedding – Flatten patches and pass through a linear projection layer
Position Embedding – Add spatial information to each patch
Transformer Encoder – Apply self attention+feedforward layers
CLS tokens – Extract global image representation
Projection head – Map the embedding into CLIP’s multimodal space
Classifier Neural Network Design:
The classifier is a fully connected deep neural network (DNN) built using TensorFlow/Keras, designed to process 768-dimensional CLIP embeddings as input. It consists of three hidden layers: the first layer has 512 neurons with ReLU activation, followed by a 256-neuron ReLU layer, and a final hidden layer with 128 neurons using ReLU activation. The output layer consists of a single neuron with a sigmoid activation function for binary classification.
The model is trained using the binary cross-entropy loss function, optimized with Adam for adaptive learning rate adjustments. Training is performed with a batch size of 32 over 20 epochs, with adjustments based on convergence. The dataset is split into 80% training and 20% testing, ensuring stratification to maintain class balance.
”The extracted embeddings are stored in a CSV file”
Gradio UI:
The gradio library is used to build a better interface which takes image as an input and predicts whether it is real or fake. The image input is given to clip model and extracts embeddings from it, then that is passed to build classifier model which predicts the output.
Results:
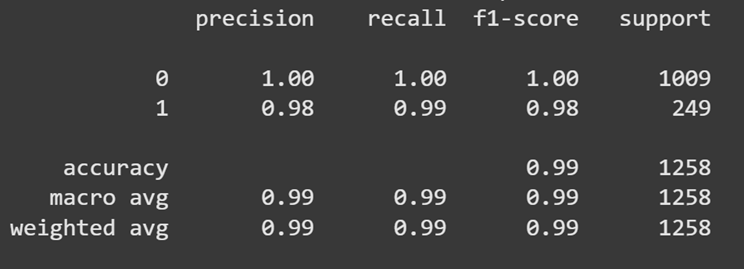
Classifier Report -
Model Performance -
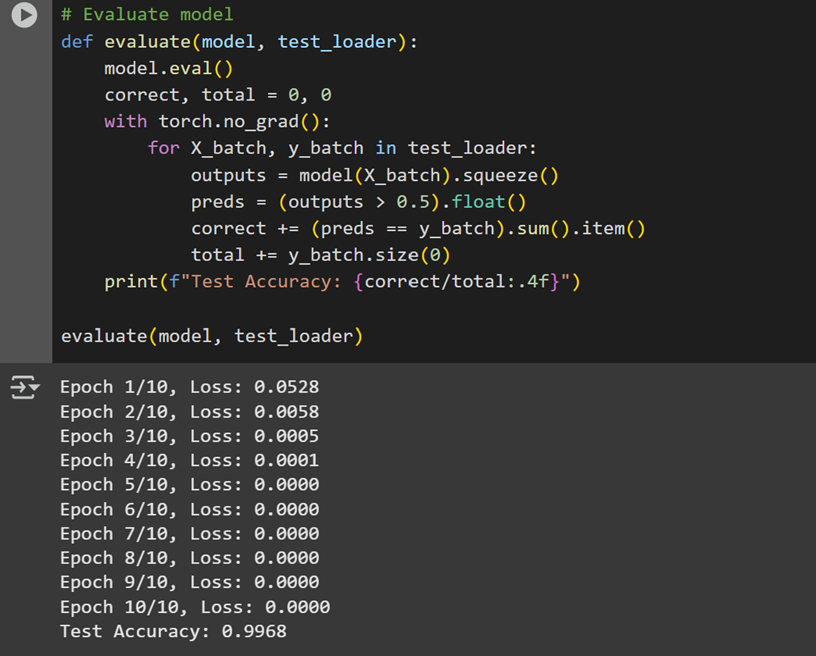



Accuracy of the Model: 0.9968
Conclusion:
A significant improvement in deepfake image detection is observed when using CLIP embeddings compared to traditional deep learning models. CLIP's multi-modal training allows it to capture high-level semantic features that general convolutional networks struggle to identify .This ability to encode semantic context rather than just pixel artifacts gives CLIP-based classifiers a clear edge over conventional architectures in deepfake detection.

References:
Mentors:
Mentees:
Report Information
Team Members
Team Members
Report Details
Created: April 6, 2025, 2:05 p.m.
Approved by: Srinanda Kaliki [Diode]
Approval date: April 7, 2025, 12:27 p.m.
Report Details
Created: April 6, 2025, 2:05 p.m.
Approved by: Srinanda Kaliki [Diode]
Approval date: April 7, 2025, 12:27 p.m.