

Text Guided Image Inpainting
Abstract
Abstract
Aim

This project explores a novel approach to image inpainting by integrating natural language descriptions into the restoration process. Inspired by how painters imagine and reconstruct missing parts of an artwork, the system uses multimodal fusion to guide inpainting with text. The method introduces adaptive text filtering and loss functions that align image restoration with textual cues, resulting in more semantically accurate and visually detailed outputs.
Introduction
In recent advancements in image processing, an intriguing new approach has emerged: using natural language descriptions to guide image restoration. This project introduces a multimodal fusion learning method (MMFL) to effectively integrate textual guidance into image inpainting, inspired by how human painters intuitively imagine and reconstruct missing image detail.
Image inpainting involves filling in missing or damaged image regions, aiming to preserve overall visual coherence and semantic accuracy. Traditional methods typically rely on surrounding pixels to synthesize missing content, struggling to accurately reproduce unique or complex features. Deep learning techniques have recently improved this task considerably but often fail to correctly infer the identity of severely occluded objects, as they primarily depend on immediate context.
Our method mimics a human painter’s behavior: when encountering damaged images, people often form an initial mental hypothesis described in words, guiding their reconstruction. Similarly, our proposed MMFL framework leverages text descriptions to steer the inpainting process accurately. By integrating textual information, our approach allows the network to effectively infer object semantics and textures in missing areas, addressing challenges that traditional or purely image-based deep learning methods face.
Specifically, our system features an innovative image-adaptive word demand module to adaptively filter unnecessary textual information, enhancing the relevant semantic guidance. Additionally, we introduce specialized loss functions—text-guided attention loss and text-image matching loss—that ensure the generated images closely align with textual descriptions, capturing detailed object characteristics and improving realism.
Through comprehensive experiments, we demonstrate that MMFL significantly outperforms existing state-of-the-art methods in generating semantically accurate and visually detailed reconstructions. Practical implications include applications such as facial attribute reconstruction for criminal investigations, where matching textual witness descriptions accurately is crucial.
This study makes several notable contributions:
- Introduces a novel text-guided multimodal fusion approach for image inpainting, demonstrating substantial potential in multimodal deep learning.
- Develops an image-adaptive word demand module to focus textual guidance precisely on missing image regions.
- Implements specialized loss functions, ensuring alignment between textual semantics and visual output.
- Provides extensive experimental validation, underscoring our method’s capability to restore detailed textures and accurately reconstruct described object attributes.
Technologies Used
Programming Languages:
Python
Libraries:
- PyTorch
- NLTK
- NumPy
- Pandas
- Matplotlib
Literature Survey
PyTorch
PyTorch, developed by Facebook AI Research (FAIR) in 2016, is an open-source deep learning framework known for its dynamic computation graph, ease of debugging, and GPU acceleration. It is widely used in computer vision, NLP, reinforcement learning, and scientific computing.
Core Features
- Tensors: Multi-dimensional arrays optimized for GPU processing.
- Autograd: Automatic differentiation for gradient computation.
- torch.nn & torch.optim: Modules for deep learning models and optimization algorithms.
- Dynamic vs. Static Graphs: Unlike TensorFlow 1.x, PyTorch allows runtime modifications.
- TorchScript & TorchServe: Converts models for efficient deployment.
- Distributed Training: Supports large-scale parallel computing.
Image Inpainting
Image inpainting is a fundamental problem in computer vision where missing or corrupted parts of an image are restored in a semantically meaningful way. Traditional image inpainting methods relied on patch-based techniques. However, deep learning, particularly Generative Adversarial Networks (GANs) and Diffusion-based Models has significantly improved results by generating realistic and high-resolution inpainted images.
Related Work
Traditional Image Inpainting Approaches
Before deep learning, classical inpainting methods were used:
- Digital Impainting Algorithm: These propagate information from surrounding pixels into missing regions but struggle with large missing areas. (Bertalmío et al., 2000).
-
Patch-based methods: These copy and blend patches from similar regions but lack high-level understanding (Barnes et al., 2009)
Deep Learning-based Image Inpainting
- Context Encoder (Pathak et al., 2016): One of the first CNN-based image inpainting methods using an encoder-decoder architecture with adversarial loss. However, it produced blurry outputs.
- Generative Adversarial Networks (GANs):
- iGAN (Zhu et al., 2016) introduced interactive image generation using GANs.
- DeepFill v1 & v2 (Yu et al., 2018, 2019) introduced partial convolutions and gated convolutions to improve results on irregular missing regions.
- EdgeConnect (Nazeri et al., 2019) proposed a two-stage GAN pipeline, first predicting missing edges and then inpainting the region.
Multi-modal (Vision-Language) Learning
Recent research integrates text guidance into image generation and inpainting:
- AttnGAN (Xu et al., 2018): Introduced an attention-based GAN architecture for text-to-image synthesis.
- DALL·E (Ramesh et al., 2021): A transformer-based model generating images from text descriptions.
- CLIP (Radford et al., 2021): A vision-language model trained on a large dataset of image-text pairs, helpful in guiding image generation and inpainting.
Text-Guided Image Inpainting
- LAMA-GAN (Zhou et al., 2021): Explored language-assisted mask-aware image inpainting using a combination of GANs and CLIP-based features.
- MMFL (Multimodal Fusion Learning) (Zhang et al., 2023): Proposed a method that combines CLIP features with AttnGAN’s DAMSM loss to enhance text-guided inpainting.
- Stable Diffusion & Text-Guided Inpainting (Rombach et al., 2022): Latent diffusion models were used for text-based image editing, including inpainting.
Key Techniques in Text-Guided Image Inpainting
Generative Adversarial Networks (GANs)
GANs consist of two networks:
- Generator: Tries to synthesize realistic inpainted images.
- Discriminator: Distinguishes between real and fake images.
Advanced techniques like StyleGAN, BigGAN, and Attention-GAN have improved controllability and realism in generation.
Vision-Language Models
CLIP Embeddings: Used to extract text-image relationships and improve image synthesis.
Transformer-based Image Generation: DALL·E and Stable Diffusion integrate transformer architectures for text-conditioned image generation.
Loss Functions for Text-Guided Inpainting
Perceptual Loss: Ensures feature similarity between generated and ground truth images.
Adversarial Loss: Helps the model generate realistic textures.
Text-Image Matching Loss (DAMSM, CLIP loss): Ensures the generated image aligns well with the provided text prompt.
Methodology
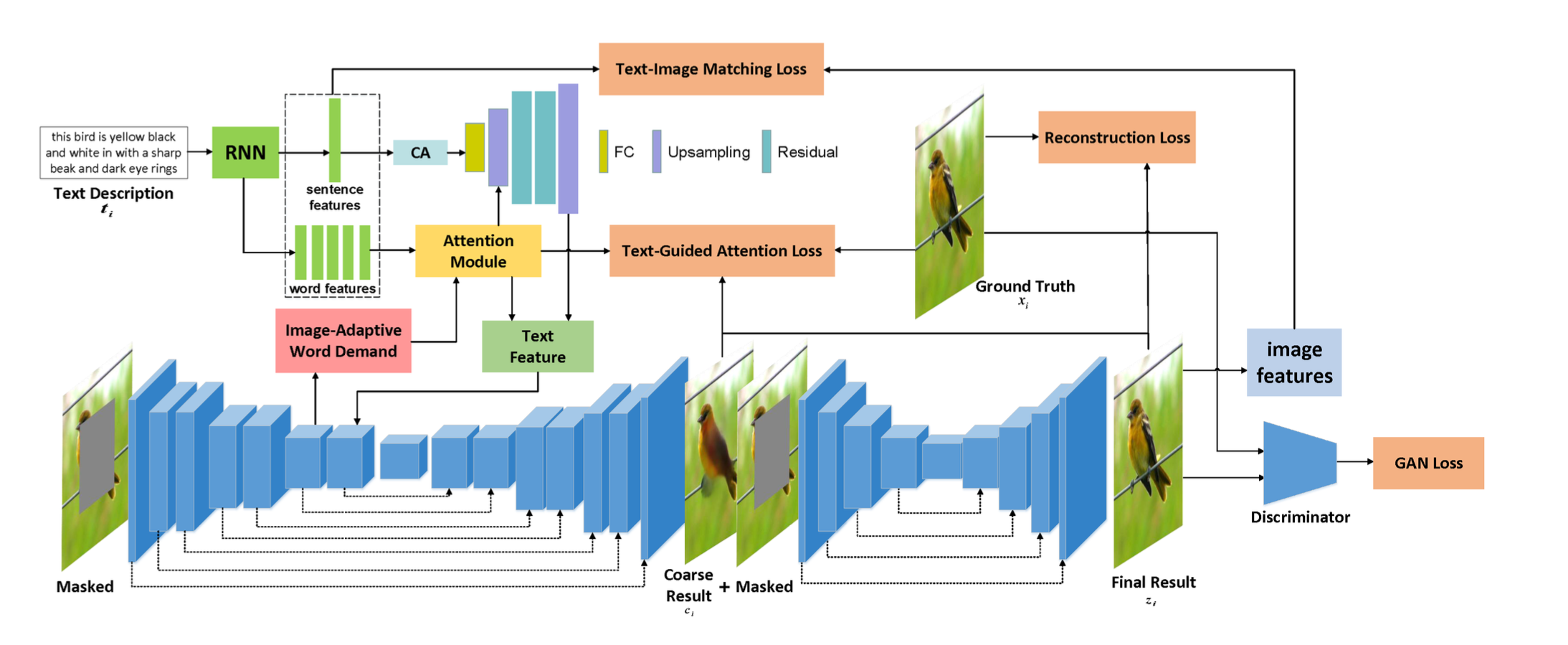
This project proposes a Multimodal Fusion Learning method (MMFL) to effectively incorporate textual descriptions into the image inpainting process, guided by a generative adversarial network (GAN) based on a U-Net structure. The inpainting is performed through a two-stage (coarse-to-fine) architecture:
Multimodal Feature Fusion
Initially, text features are extracted using a pre-trained bidirectional recurrent neural network (RNN), obtaining sentence-level and word-level features. These textual features undergo conditioning augmentation and are refined by an attention module, aligning them with image features within a unified feature space.
To ensure the relevance of textual guidance, we introduce an Image-Adaptive Word Demand Module (WDM), which selectively emphasizes critical word features based on the current visual context of the image. This module adaptively calculates feature importance, dynamically adjusting the textual input to focus precisely on missing image content.
Image-Adaptive Word Demand Module
The WDM utilizes intermediate features extracted from the encoder's fourth layer. It produces two feature blocks representing local and global information by applying convolution operations and reshaping. Multiplying these feature blocks yields an attention map that indicates word importance, weighting the word embedding accordingly. This adaptive approach ensures targeted and contextually relevant textual guidance.

Loss Functions
Assume that the training image set 𝑋 is defined as: 𝑋 = {𝑥1, 𝑥2, · · · , and each image has its corresponding text set defined as: 𝑇 = {𝑡1, 𝑡2, · · · , 𝑡𝑚}.
By removing the masked area from 𝑥𝑖 and using the feature information of the corresponding reference 𝑡𝑖, the generator first gets a coarse inpainting result 𝑐𝑖 and finally generates a new restoration image 𝑧𝑖.
Four loss functions are employed to optimize the image generation process:
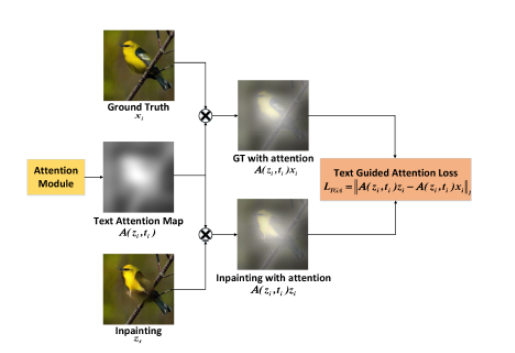
Text Guided Attention Loss (TGA) emphasizes important object characteristics indicated in textual descriptions, helping the network prioritize the correct details in the missing regions.
ℒ𝑇𝐺𝐴 = ‖𝒜(𝑧𝑖, 𝑡𝑖)𝑧𝑖 − 𝒜(𝑧𝑖, 𝑡𝑖)𝑥𝑖‖
Text-image Matching Loss (TIM) ensures semantic alignment between the generated images and their respective textual descriptions by computing similarities within a shared feature space.
ℒ𝑇𝐼𝑀 = ℒ𝑊𝑜𝑟𝑑 + ℒ𝑆𝑒𝑛𝑡𝑒𝑛𝑐𝑒
ℒ𝑊𝑜𝑟𝑑 is the negative log posterior probability between the local region of the image and the corresponding words
Reconstruction Loss ensures visual fidelity by minimizing differences between generated images and ground truth.
ℒ𝑅𝑒𝑐 = ‖𝑧𝑖 − 𝑥𝑖‖1 + ‖𝑐𝑖 − 𝑥𝑖‖
GAN Loss promotes realism by training the discriminator to distinguish between generated and actual images.
ℒ𝐺𝐴𝑁 = ℰ𝑥𝑖∼𝑝𝑑𝑎𝑡𝑎(𝑥)[𝑙𝑜𝑔𝒟(𝑥𝑖)] + ℰ𝑧𝑖∼𝑝𝑧 [𝑙𝑜𝑔(1 − 𝒟(𝒢(𝑧𝑖)))]
The total loss function integrates these components with corresponding weights to balance their influence, ensuring robust and high-quality image restoration.
Results
Through extensive experimentation, our GAN-based image inpainting model proved to be highly effective in generating context-aware and visually coherent reconstructions based on textual prompts. The model successfully restored missing regions with remarkable precision, seamlessly blending them into the surrounding image. By incorporating modern research advancements and optimization techniques, we enhanced the base implementation, achieving significant improvements in output quality. Additionally, we developed an interactive web application, enabling users to experience real-time text-guided image inpainting in an intuitive and accessible manner. The results exceeded expectations, demonstrating the model’s ability to handle complex inpainting scenarios with high accuracy. Furthermore, utilizing open-source frameworks and efficient deep learning techniques, our work provides a scalable and practical approach for future research and real-world applications in generative AI.

Future Scope
There are many further potential improvements. For example, we do experiments on three datasets, which all contain the same class of objects, and the network learning is more targeted. However, our method performs poorly for datasets with various objects (For example, COCO). In the future, we will use masks covering the object area or free-form masks to make the text description more closely related to the masked area, which may lead to better results.
Additionally, integrating diffusion-based models could enhance inpainting quality, particularly for complex datasets, by improving structural consistency and finer details. Incorporating vision-language models like CLIP may also improve semantic alignment between text prompts and generated content.
Future work can explore real-world applications such as photo restoration, object removal, and medical image reconstruction, with a focus on optimizing the model for real-time inference. Lastly, adopting self-supervised learning and efficient transformer-based architectures could further improve generalization and computational efficiency.
References
MMFL: Multimodal Fusion Learning for Text-Guided Image Inpainting
Introduction to Generative models for Image Inpainting
Generative Adversarial Networks
GitHub Repository
The source codes can be found here.
Acknowledgment
As executive members of IEEE NITK, we are deeply grateful for the opportunity to learn and contribute to this project under the esteemed banner of the IEEE NITK Student Chapter. We sincerely appreciate IEEE’s generous support and funding, which played a crucial role in the successful completion of this project.
Report Information
Team Members
Team Members
Report Details
Created: April 6, 2025, 5:47 p.m.
Approved by: Abhin B [CompSoc]
Approval date: April 7, 2025, 4:31 p.m.
Report Details
Created: April 6, 2025, 5:47 p.m.
Approved by: Abhin B [CompSoc]
Approval date: April 7, 2025, 4:31 p.m.