

Accent Classification Using Deep Learning
Abstract
Abstract
Aim:
To develop an accurate accent classification model using deep learning techniques, leveraging pretrained speech models, and providing an interactive interface through Gradio.
Literature Survey :
Traditional approaches to accent and speaker classification have relied on acoustic features such as MFCCs (Mel-Frequency Cepstral Coefficients), pitch contours, and spectral patterns. These methods, while interpretable, often fall short in modeling complex patterns across time. More recent advancements have adopted deep learning, including convolutional and recurrent architectures, which can automatically learn temporal dependencies and extract high-level features from raw or processed audio. However, such models require substantial data and computational resources. Self-supervised models like Wav2Vec2 have demonstrated strong performance in various speech-related tasks, learning useful representations from large unlabeled corpora. These embeddings can be fine-tuned or used directly for downstream tasks like accent classification with remarkable success.
Dataset :
The dataset used in this project was sourced from the Speech Accent Archive, which contains recordings of speakers from diverse linguistic backgrounds reading the same paragraph in English.
Key Points:
- Languages Included: English, Mandarin, Russian, Arabic, and several Indian languages.
- Speaker Selection: Only male speakers were selected to ensure demographic consistency and reduce confounding factors during training.
- Data Acquisition: The archive does not provide a mass-download feature. A Python web scraper was developed to extract metadata and download links. One script scrapes speaker data (language, gender, region, etc.) and saves it into a CSV. A second script downloads the associated .wav files using the extracted URLs.
This approach ensured scalable, structured, and reproducible data collection from the archive.
Methodology:
1. Feature Extraction
We experimented with various audio feature extraction techniques, including:
-
MFCCs
-
Mel Spectrograms
-
Parselmouth-based features
However, these traditional features yielded suboptimal performance (60– 74% accuracy), prompting a shift toward more powerful representations.
The final model used the pretrained Wav2Vec2.0 model (facebook/ wav2vec2-base-960h) to extract features:
-
Each audio file was passed through Wav2Vec2.0 to obtain 768- dimensional embeddings.
-
Since the model outputs a sequence of embeddings over time, we applied mean pooling across the time dimension to get a single fixedlength vector per audio.
-
Accent labels were mapped to numerical values for supervised training.
This approach yielded significantly better generalization and performance than traditional feature sets.
2. Class Imbalance Handling :
A major challenge was the imbalance in the number of samples across accents. For example, there were significantly more recordings for English accents than Mandarin.
To address this:
-
We applied SMOTE (Synthetic Minority Oversampling Technique) to oversample underrepresented classes by generating synthetic samples in the feature space.
-
This helped balance the dataset and mitigate model bias toward dominant classes.
-
After applying SMOTE, the model exhibited improved generalization, especially for low-resource accents like Mandarin.
Classifier Architecture :
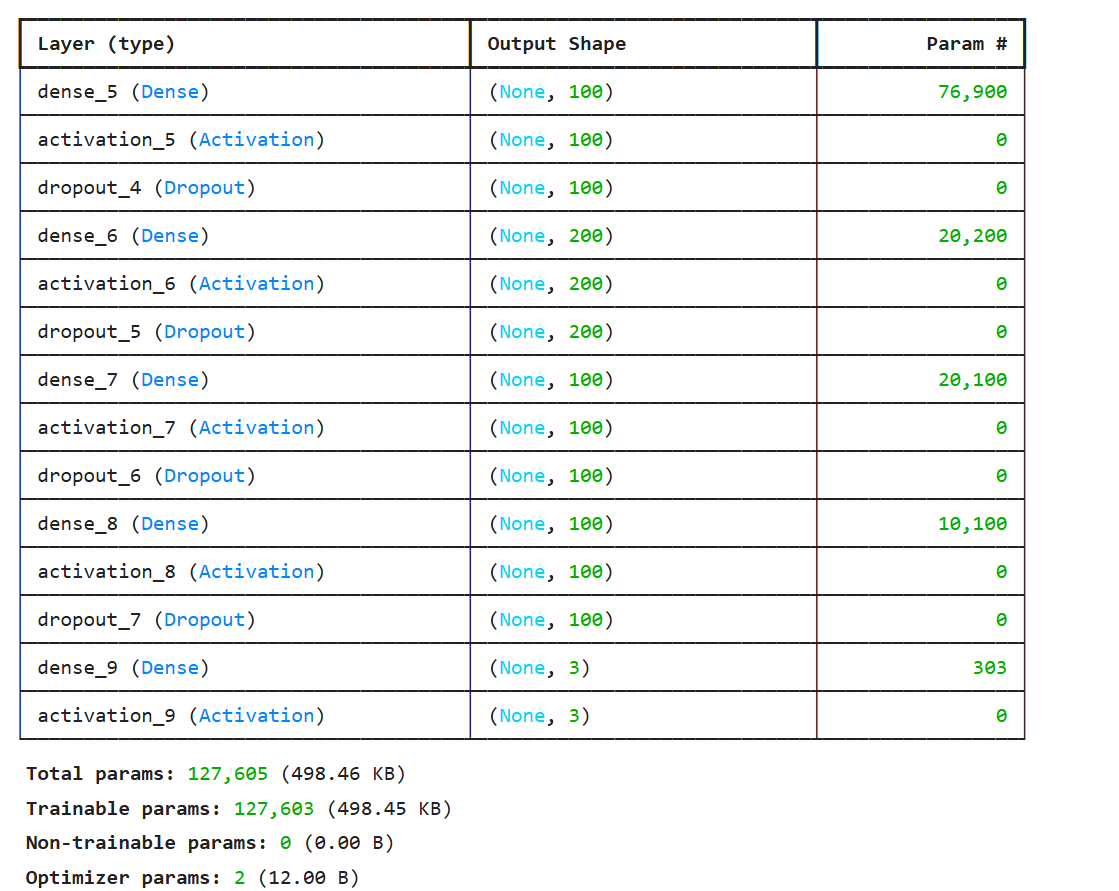
The classifier was implemented as a feedforward neural network using TensorFlow/Keras.
-
Input: 768-dimensional vectors from Wav2Vec2
-
Architecture: Multiple dense layers with ReLU activation and Dropout (0.5) for regularization Softmax output layer for multi-class classification
-
Training Details: Optimizer: Adam Loss: Categorical Cross-Entropy Batch size: 32 Epochs: 20 Validation split: 20% This simple architecture was sufficient due to the rich representation provided by the Wav2Vec2 embeddings.
Results
Performance Summary:
| Feature Type | Accuracy |
|---|---|
| Mel-Spectrograms | ~60% |
| MFCCs | ~70% |
| Parselmouth Features | ~74% |
| Wav2Vec2 (raw) | ~86% |
| Wav2Vec2 + SMOTE | 92.41% |
Key Observations:
-
English and Arabic accents were classified with high accuracy.
- Mandarin initially performed poorly due to lack of data but improved after SMOTE balancing.
- Confusion Matrix: Errors were mostly between closely related accents.
- t-SNE Visualization: Showed distinct clusters for each accent, validating that Wav2Vec2 embeddings captured meaningful accentspecific characteristics.
Discussion:
-
Wav2Vec2-based embeddings significantly outperformed traditional acoustic features.
- SMOTE oversampling was critical in improving performance on minority classes.
- Web scraping enabled flexible, reproducible data collection without relying on third-party datasets.
Gradio Interface :
To make the model easily accessible and user-friendly, we developed an interactive Gradio-based interface.
Features:
- Audio Input Options: Upload .wav files ,,Record audio live via microphone
- Preprocessing: Audio is normalized and fed to the Wav2Vec2 model. Embeddings are extracted and mean pooled in real-time.
- Live Prediction: The model classifies the accent and displays confidence scores. This web-based UI makes the system suitable for deployment and demonstration purposes, bridging the gap between model development and end-user interaction.
Future Work :
While the current model demonstrates strong performance, several directions for improvement remain:
- Expand Dataset: Include more speakers and accents from a wider range of demographics and regions.
- Include Female Speakers: Expand beyond male-only data for better representational balance.
- Fine-Tune Wav2Vec2: Rather than just using frozen embeddings, future versions could fine-tune the model on accent-specific tasks.
- Balance Data Further: Especially for Mandarin and other lowresource classes.
- Try New Architectures: Use CNNs, RNNs, or transformer-based models for better temporal feature modeling.
- Multitask Learning: Extend the system to predict gender or regional sub-accents as well.
- Real-Time Applications: Integrate into live speech applications like assistants, transcription tools, or education platforms.
- Contribute to Indian Language Datasets: One of our long-term goals is to help build and share a public dataset of Indian accents, as existing resources are extremely limited.
Conclusion :
This project demonstrates that combining powerful self-supervised models like Wav2Vec2 with a simple yet effective neural classifier can result in highperforming accent classification systems. With proper preprocessing, feature extraction, and class balancing (via SMOTE), our system achieved a strong accuracy of over 92% across several accent categories. Through extensive experimentation, we found that Wav2Vec2 embeddings significantly outperformed traditional features such as MFCCs, Mel Spectrograms, and Parselmouth-derived features. The success of this approach also highlights the importance of using rich, context-aware representations for complex linguistic tasks like accent recognition. While the model performed particularly well for English and Arabic, it initially struggled with Mandarin, largely due to data imbalance—a problem mitigated by oversampling. Another limitation we faced was the lack of sufficient samples for Indian language accents. Although we attempted to include them, the small dataset size prevented us from training a robust classifier for those accents. As part of our future goals, we aim to actively contribute to building Indian accent datasets, helping bridge this gap in the speech research community. Enhancing linguistic inclusivity is critical to creating equitable and effective AI systems. The Gradio-based interface adds an accessible, real-time interaction layer to the model, making it suitable for end users, demos, and potential integrations into real-world applications. In summary, this project lays a strong foundation for accent-aware speech applications, with clear paths forward for broader coverage, better fairness, and more impactful real-world use.
References: :
https://www.iosrjournals.org/iosr-jce/papers/Vol25-issue2/Ser-3/B2502031116.pdf
https://cs229.stanford.edu/proj2017/final-reports/5244230.pdf
https://www.youtube.com/playlist?list=PLhA3b2k8R3t2Ng1WW_7MiXeh1pfQJQi_P
Report Information
Team Members
Team Members
Report Details
Created: April 7, 2025, 4:47 p.m.
Approved by: Jayavarapu Surya Abhinai [Diode]
Approval date: None
Report Details
Created: April 7, 2025, 4:47 p.m.
Approved by: Jayavarapu Surya Abhinai [Diode]
Approval date: None